
Content Indexes
A content index is an index of page content on a solution – typically all pages, paragraphs, and various item instances. This type of index is built by enumerating all available pages and then indexing all active paragraphs and items associated with each page. A content index is typically built to make it possible to search for content on a website.
To create a content index:
- Go to Settings > Repositories and open/create a repository
- Click Add index in the toolbar
- Name it
- Click OK
This creates an empty index (Figure 1.1) – you should now add instances to it.
Adding Instances
An instance is a file in the file archive – it is this file which is being searched when a query is executed. Since instances are often rebuilt to make sure they contain the most recent changes you want to create at least 2 instances. This ensures that there’s always an instance to search, even if one instance is currently being rebuilt.
Create at least two instances:
- Click Add instance
- Provide a name – you could call one instance ‘Content A’ and the other instance ‘Content B’
- Specify a folder to place the instance file under
- Click OK
Once created an instance will look like:
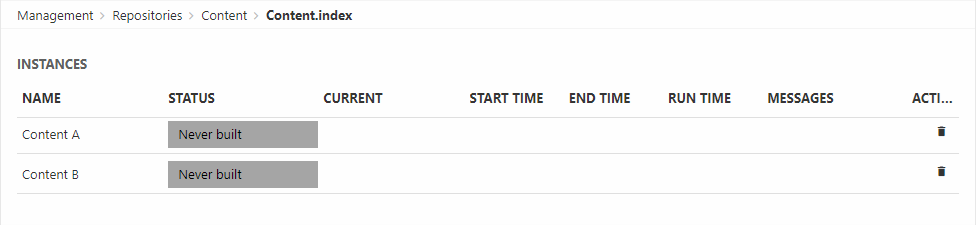
When an instance is built a set of index files are generated under System/Indexes/YourIndexName/YourInstanceName – but before you can build it you must create a build configuration.
Adding a build configuration
So now that you have two instances you want to build them – to do so you need to create a build definition.
Each type of index has a specific builder associated with it – in the case of a content index this builder is helpfully called the ContentIndexBuilder. It builds the index by enumerating all available pages, then indexing active pages and items for each page.
To add the build configuration:
- Click Add build
- Provide a name
- Select the ContentIndexBuilder
- Select a builder action – only Full is currently available
- Review the builder settings
- Set up notifications if appropriate
- Click OK
The following builder settings are available – please review carefully to see if any of them are relevant for your setup:
|
Setting |
Value |
Comments |
|
ExcludeItemsFromIndex |
Boolean – default is false |
Set to true to exclude item content from the index |
|
SkipPageItemRelationLists |
Boolean - defaults to False |
|
|
SkipParagraphItemRelationLists |
Boolean – defaults to False |
|
|
AppsToHandle |
- |
Allows you to specify which ContentAppIndexProviders to include – defaults to all, unless a comma separated list of providers is set as the value. We only provide one – for the Forum app – but you can create a class inheriting from the ContentAppIndexProvider class and build your own. |
So now you’ve specified how you want the index to be built – you should now specify what you want to include in the index.
Adding fields
Lucene indexes are composed of small documents, with each document divided into named fields which contain either content which can be searched or data which can be retrieved. Each field added to the index can therefore be stored, indexed, and analyzed depending on what you want to use it for:
- Stored fields have their values stored in the index
- Indexed fields can be searched, the value is stored as a single value
- Analyzed fields have their values run through an analyzer and split into tokens (words)
Generally speaking, a field you want to display in frontend must be indexed and a field where you want the user to search for parts of the value in free-text search must be analyzed. Field which are to be published using the query publisher should be stored.
To make things (a lot) easier for you we’ve created a default set of fields typically used in content indexes – this default field set is defined in something called the ContentIndexSchemaExtender.
To add the fields from the schema extender to the index:
- Click Add field
- Select the schema extender field type
- Select the ContentIndexSchemaExtender
- Click OK
This adds a whole bunch of fields to the index (Figure 4.1).
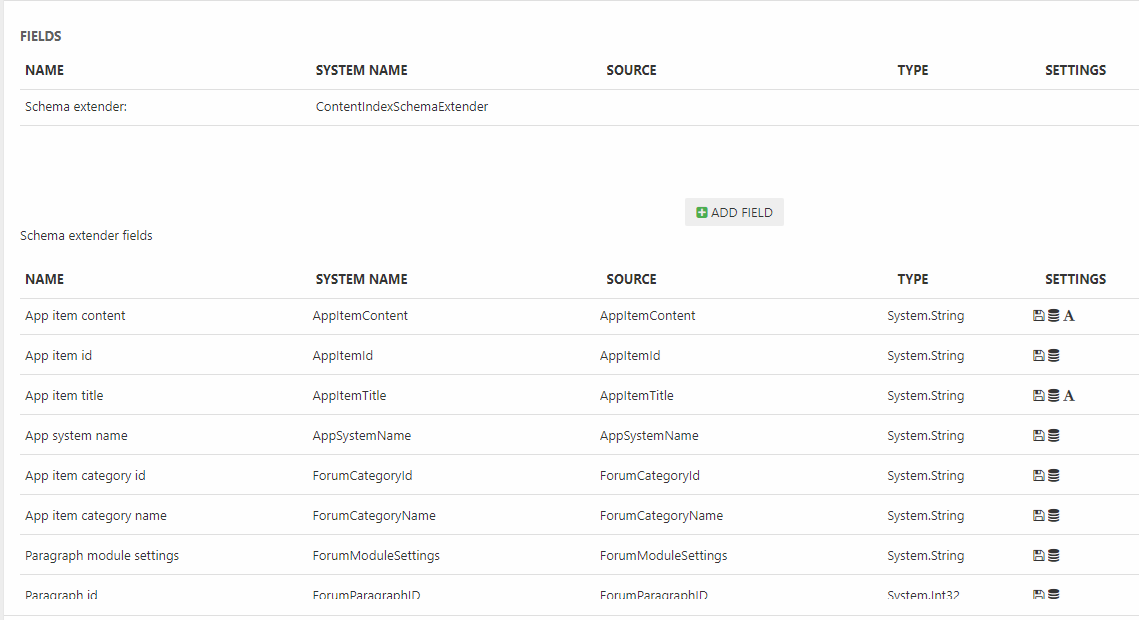
The ContentIndexSchemaExtender contains the following type of fields:
- All fields from the Page table – e.g. PageActive, PageID, PageItemType, etc.
- A number of Page content fields:
- Paragraph headers contains an array of all paragraph headers on a page
- Paragraph texts contains an array of all paragraph text content on a page
- Paragraph content contains an array of the item type properties for each item-based paragraph on a page
- Page property item type contains the name of the item type used to extend the page properties of this page (if relevant)
- All item type fields in the format [item.SystemName]_[itemField.SystemName] and Property_[item.SystemName]_[itemField.SystemName], except the fields marked as 'do not include in search' in the item field settings.
- Possibly a number of App fields from a Forum app
Due to complexity issues the ItemListEditor field type is never indexed.
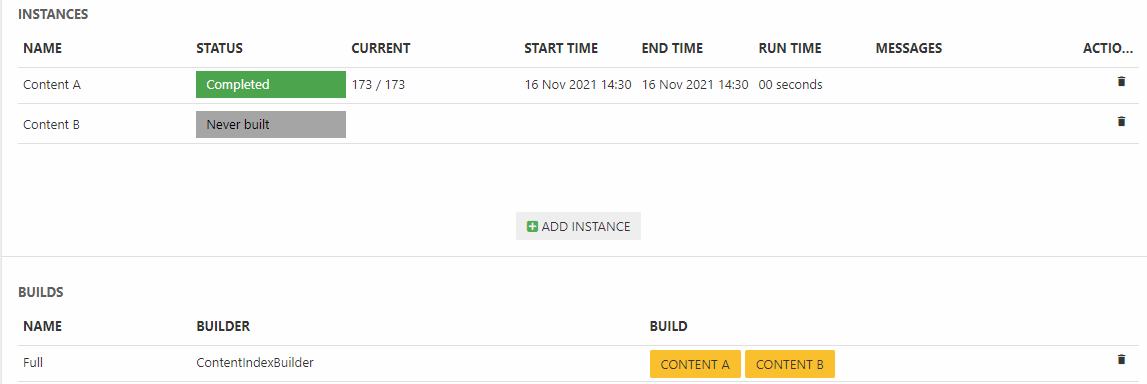
Building the index
Once you’ve added instances, a build configuration, and a set of fields to the index you should build it – to do so click a yellow button with an instance name on it (Figure 5.1).
Of course, you don’t want to do this manually every time, you want to rebuild the index on a schedule – see the article on tasks.
If you have more than three instances defined you can also choose between two different balancing methods for selecting an alternative index when the primary index is being built:
- Click Balancer in the toolbar
- Choose between the two modes:
- ActivePassive selects the next instance on the list of instances – so if instance A is unavailable (building, has failed), instance B will be used unless it’s unavailable, in which case instance C will be used, and so on.
- LastUpdated selects the most recently built index
On solutions with heavy traffic and frequent product data updates we recommend using the LastUpdated mode to ensure that visitors are always shown the most recently updated product data. On solutions with only two instances (the vast majority of solutions) it is not necessary to select a balancer mode, as the “other index” will always be used when an index is unavailable.