
Product Indexes
A product index is an index of product data on a solution – typically all standard and custom product fields as well as a lot of generated fields with additional information which is useful when publishing products to frontend (1), rendering facets (2), and for backend tasks in e.g. PIM.
To create a product index:
- Go to Settings > Repositories and open/create a repository
- Click Add index in the toolbar
- Name it
- Click OK
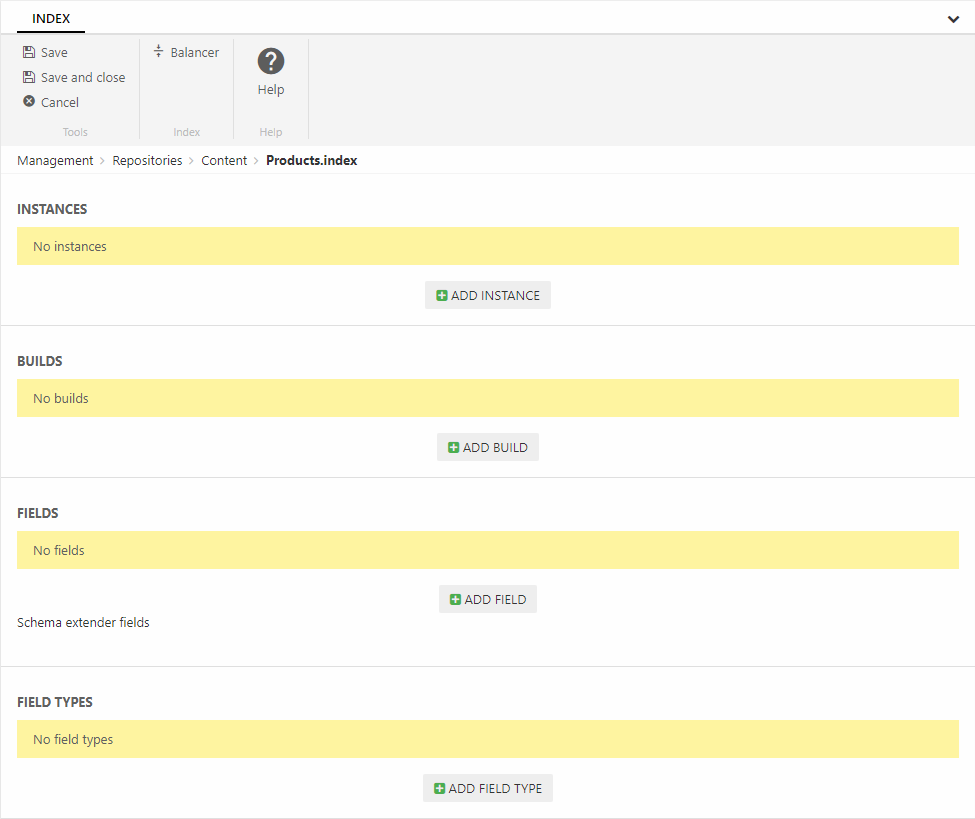
This creates an empty index (Figure 1.2) – you should now add instances to it.
Adding Instances
An instance is a file in the file archive – it is this file which is being searched when a query is executed. Since instances are often rebuilt to make sure they contain the most recent changes to product data you want to create at least 2 instances. This ensures that there’s always an instance to search, even if one instance is currently being rebuilt.
Create two instances:
- Click Add instance
- Provide a name – you could call one instance ‘A’ and the other instance ‘B’
- Specify a folder to place the instance file under
- Click OK
Once created an instance will look like:
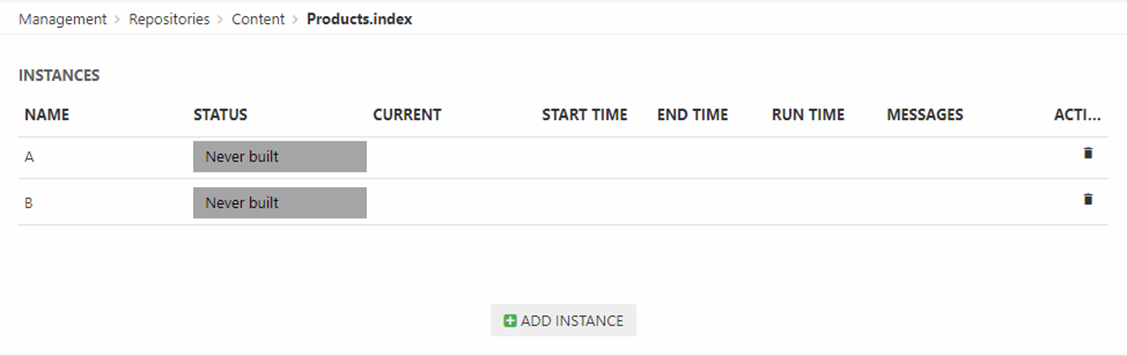
When an instance is built a set of index files are generated under System/Indexes/YourIndexName/YourInstanceName – but before you can build it you must create a build configuration.
Adding a build configuration
So now that you have two instances you want to build them – to do so you need to create a build definition. Each type of index has a specific builder associated with it – in the case of a product index this builder is helpfully called the ProductIndexBuilder.
To add the build configuration:
- Click Add build
- Provide a name
- Select the ProductIndexBuilder
- Select a builder action:
- Full rebuilds the whole index
- Update rebuilds the products which have edited in the timespan between the current time and the HoursToUpdate builder setting
- UpdateWithIds is a mode used by the system to update smaller batches of products as they are saved in e.g. PIM
- Review the builder settings
- Set up notifications if appropriate
- Click OK
The following builder settings are available – please review carefully to see if any of them are relevant for your setup:
|
Setting |
Value |
Comments |
|
BulkSize |
Integer – default is 500 |
The number of products being built at a time |
|
DoNotAnalyzeDefaultFields |
Boolean – defaults to false |
If True, schema extender fields not set to analyzed by default |
|
DoNotStoreDefaultFields |
Boolean – defaults to false |
If True, schema extender fields are not set to stored by default |
|
DoNotFailOnMismatchingProductCount |
Boolean – defaults to false |
If true, building an index will not fail even if the product count before indexing and after indexing is different. This may be desirable if an import job happens while the index is being built. |
|
EmptyStringReplacement |
String – default is an empty string |
NULL values are not indexed by Lucene, so to be able to locate an empty field you need to index it with a dummy value – this dummy value can be specified here. |
|
HandleInheritedCategoryValues |
Boolean – defaults to false |
If True, inherited product category values are indexed. This is very slow, so please don't set this to true unless you really need to. |
|
HoursToUpdate |
An integer – not set by default |
If combined with the builder action Update, only the products updated within the hours specified here are rebuilt |
|
MaxProductsToIndex |
Integer – default is 2147483647 |
The maximum number of products to index |
|
OnlyIndexActiveProducts |
Boolean – defaults to false |
If set to True, only active products are indexed |
|
ShopsToIndex |
Comma-separated list of shop IDs |
This setting makes it possible to create indexes which only contain products from the specified shops/warehouses. |
|
SkipAllExtendedFields |
Boolean – defaults to false |
If set to True, the fields "CampaignStartTime", "CampaignEndTime", "CampaignShowProductsAfterExpiration", "IsVariant", "ManufacturerName", "AssortmentIDs", and "StockLocationProductAvailable" are skipped |
| SkipAssortments | Boolean – defaults to false | If set to True, assortments are not indexed |
| SkipCampaign | Boolean – defaults to false | If set to true, campaign information is not indexed |
|
SkipCategoryFields |
Boolean – defaults to false |
If set to True, all product category fields are skipped |
|
SkipDetailImages |
Boolean – defaults to false |
If set to true, Details images are not indexed |
|
SkipExtenders |
Boolean – defaults to False |
If set to True, no custom Extenders can extend (update, remove, add) the fields in the index |
|
SkipGrouping |
Boolean – defaults to false |
If set to True, the fields "GroupIDs", "ShopIDs", "GroupNames", |
|
SkipGroupSorting |
Boolean – defaults to false |
If set to true, group sorting fields are not indexed – this may improve performance. |
|
SkipImages |
Boolean – defaults to false |
If true, image paths are not indexed |
|
SkipImagePatternImages |
Boolean – defaults to false |
If true, image pattern images are not indexed |
| SkipOrderhistory | Boolean – defaults to false | If true, details about the order history of products are not indexed |
|
SkipPrices |
Boolean – defaults to false |
If true, product prices are not indexed |
|
SkipRelatedProducts |
Boolean – defaults to false |
If true, related products are not indexed |
So now you’ve specified how you want the index to be built – you should now specify what you want to include in the index
Adding fields
Lucene indexes are composed of small documents, with each document divided into named fields which contain either content which can be searched or data which can be retrieved. Each field added to the index can therefore be stored, indexed, and analyzed depending on what you want to use it for:
- Stored fields have their values stored in the index
- Indexed fields can be searched, the value is stored as a single value
- Analyzed fields have their values run through an analyzer and split into tokens (words)
Generally speaking, a field you want to display in frontend must be indexed and a field where you want the user to search for parts of the value in free-text search must be analyzed. Field which are to be published using the query publisher should be stored. Fields you want to display as facets should be indexed but not analyzed.
To make things (a lot) easier for you we’ve created a default set of fields typically used in product indexes – this default field set is defined in something called the ProductIndexSchemaExtender.
To add the fields from the schema extender to the index:
- Click Add field
- Select the schema extender field type
- Select the ProductIndexSchemaExtender
- Click OK
This adds a whole bunch of fields to the index (Figure 4.1).
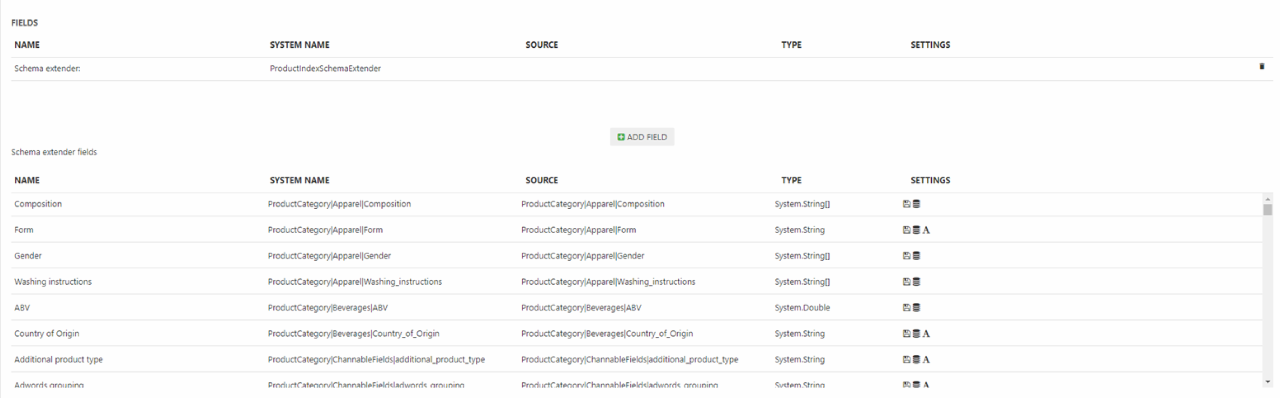
Most of these fields are standard product fields and various types of custom fields such as product category fields, but there’s also a whole bunch of field which are generated whenever the index is rebuilt e.g. the BoughtWithProducts field, the GroupIDs field, and many others. For each field you can see the Name, System Name, Source and Type – and whether or not the field is stored, indexed and analyzed.
As you can see, all String-type fields are analyzed by default, which is ideal if you want to include them in e.g. a free-text query – but it may be a problem if you want to e.g. create facets based on the field. Fortunately you can also add fields to the index manually – see the Custom Fields article.
Building the index
Once you’ve added instances, a build configuration, and a set of fields to the index you should build it – to do so click a yellow button with an instance name on it (Figure 5.1).
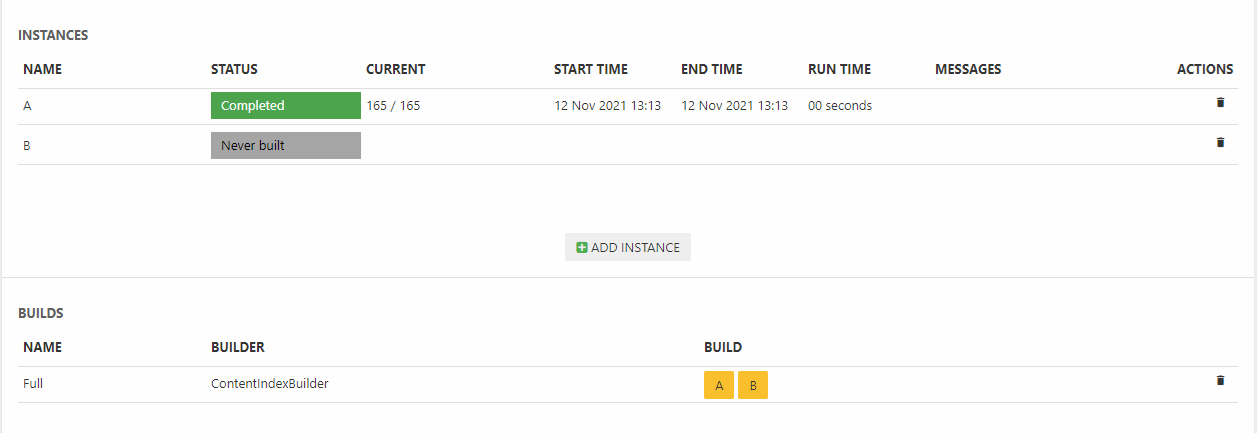
Of course, you don’t want to do this manually every time – you want to do a combination of the following:
- Rebuild the index every time an integration job has been executed
- Rebuild the index every time a product is saved in PIM
- Rebuild the index on a schedule – see the article on tasks
If you have more than three instances defined you can also choose between two different balancing methods for selecting an alternative index when the primary index is being built:
- Click Balancer in the toolbar
- Choose between the two modes:
- ActivePassive selects the next instance on the list of instances – so if instance A is unavailable (building, has failed), instance B will be used unless it’s unavailable, in which case instance C will be used, and so on.
- LastUpdated selects the most recently built index
On solutions with heavy traffic and frequent product data updates we recommend using the LastUpdated mode to ensure that visitors are always shown the most recently updated product data. On solutions with only two instances (the vast majority of solutions) it is not necessary to select a balancer mode, as the “other index” will always be used when an index is unavailable.
Optimizing the index
Speed is king, and once your project moves into the staging and production phases you may well find that you want to go faster. If that’s the case you can tweak some of the build configuration settings and improve your performance.
Here are some of the settings which will give you the most bang for the buck:
- Set SkipPrices to true
By default, we index prices – but only base prices, so unless you’re going to do some fairly complicated logic in frontend to account for e.g. Discounts you may want to set this setting to true. - Set SkipImagePatternImages or SkipDetailImages to true
Solutions typically either use images from image patterns or the so-called Detail Images. Whenever you use one, set the other to true to improve performance. - SkipGroupSorting = true
If your solution does not use group sorting fields in frontend you can disable this to improve performance.
In general it’s a good idea to review the various build configuration options and see what data you actually want to use.