Indexes
An index is a data structure optimized for data retrieval operations – which means that querying it is much faster than searching through each row in the database whenever a table is accessed.
To create an index:
- Click Add index in the repository toolbar (Figure 1.1)
- Name it
- Click OK
This will open the index configuration page (Figure 1.2) from which you can add and configure the various index components.
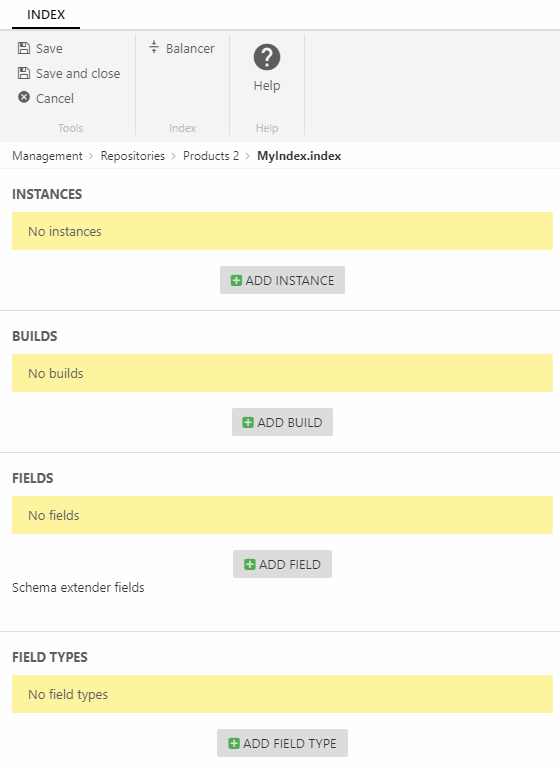
An index consists of the following components:
- Instances – the data structures which are queried
- Build configurations – a set of instructions for retrieving data from Dynamicweb and building an instance
- Field definitions – a set of instructions detailing what goes in the index and how it should be stored
- (Optional) Field types – custom field types can be used when you need to analyze data in a non-standard manner.
Read about the components below.
Instances
Instances are used to specify a location and an IndexProvider, which will create the index files at the location.
By default, Dynamicweb uses Lucene 3.0.3 and comes with a LuceneIndexProvider which builds index files in a folder in the file archive, e.g. /Files/System/Indexes/YourIndexName/YourInstanceName.
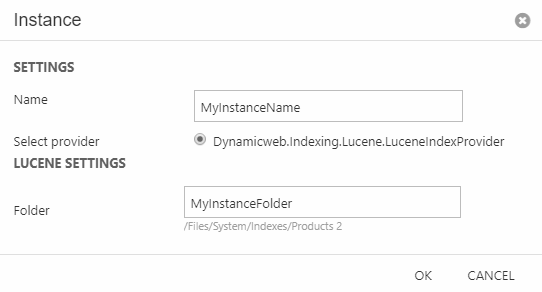
To create an instance:
- Click Add instance on the index configuration page to open the Instance configuration (Figure 2.1)
- Provide a name
- Select a provider – this step is easy, as we supply only one provider out of the box
- Specify a folder
- Click OK
Once created, an instance will look like the Lucene B index in Figure 2.2 – this is because it has not been built yet. Once it has been built it will look like the Lucene A index.

An instance only contains the data which existed at the time it was built. This means that your instances must be periodically rebuilt to include new data - and that you should always have more than one instance defined, since indexes cannot be queried when they are being built.
You can create scheduled tasks for automatically rebuilding your instances at an interval – see details below – and these tasks will build the instances sequentially, and will not rebuilt the last index if the previous instanced failed to be built correctly. This means that you will never be without an instance to query – even if something goes wrong during the built process.
Balancing instances
If you have more than three instances defined, you can choose between two different methods for selecting an alternative index when the primary index is being rebuilt:
- ActivePassive mode selects the next active instance available on the list. So if instances A is unavailable (being built, has failed to build), instance B will be used unless it is unavailable, in which case instance C will be used, and so forth
- LastUpdated mode selects the most recently built index and uses that
ActivePassive mode is used by default – to change to LastUpdated mode:
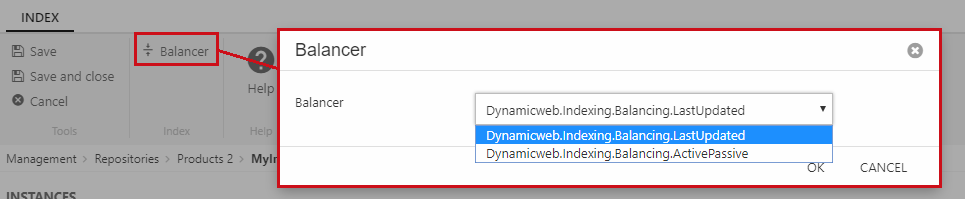
- Click Balancer in the ribbon bar (Figure 3.1)
- Use the dropdown to select the LastUpdated balancer
- Click OK
For solutions receiving heavy traffic and frequent product data updates we recommend using LastUpdated to ensure that visitors are always shown the most recently updated data.
Builds
A build is a set of instructions for retrieving data from Dynamicweb and delivering it to the IndexProvider on an instance, which will then build the physical index files.
To create a build configuration:
- Click Add build on the index configuration page to open the build configuration dialog
- Provide a name
- Select a builder
- (Optional) Configure the settings exposed by the builder
- (Optional) Set up notifications on run or failure
- Click OK
See below for a detailed look at the builders provided by Dynamicweb.
ProductIndexBuilder
The ProductIndexBuilder is used to index products. It indexes data from multiple Ecommerce data tables, calculating group hierarchies and more – so the index contains all products fields, variant group fields, custom fields, category fields, stock location fields and a number of generated fields.
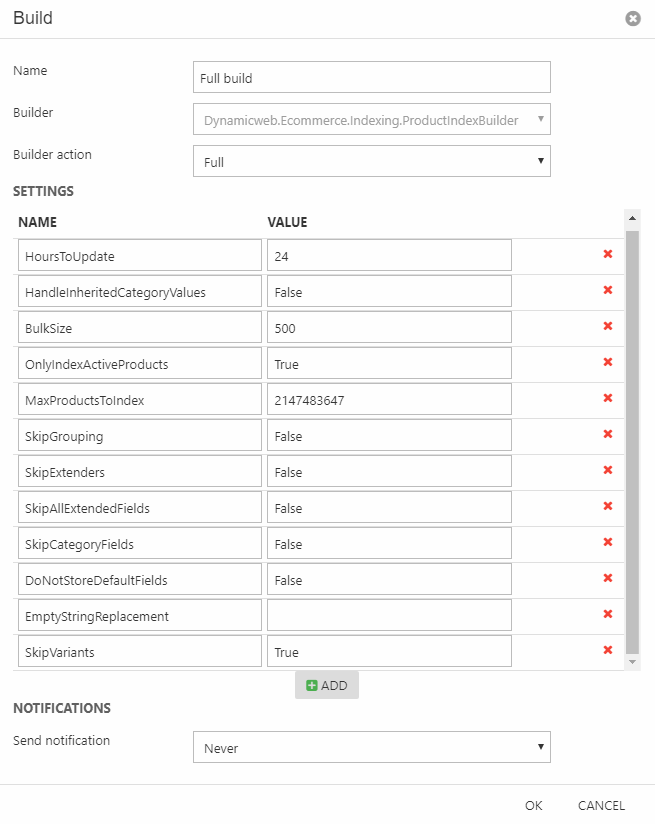
The ProductIndexBuilder supports the following builder actions:
- Full builds everything from scratch
- Update rebuilds only the products which have been edited within the timespan which falls between the current time and the HoursToUpdate setting
- UpdateWithIds is a mode used by auto-builds from e.g. Dynamicweb PIM. Although this action cannot be called manually with a list of Ids, we recommend creating a separate builder action called AutoBuild to avoid conflicts between regular Update build and auto-builds.
The following settings can be configured:
|
Setting |
Value |
Comments |
|
BulkSize |
Integer – default is 500 |
The number of products being built at a time |
|
DoNotAnalyzeDefaultFields |
Boolean - defaults to False |
If True, schema extender fields not set to analyzed by default |
|
DoNotStoreDefaultFields |
Boolean – defaults to False |
If True, schema extender fields are not set to stored by default |
|
DoNotFailOnMismatchingProductCount |
Boolean - defaults to False |
If true, building an index will not fail even if the product count before indexing and after indexing is different. This may be desirable if an import job happens while the index is being built. |
|
EmptyStringReplacement |
String – default is an empty string |
NULL values are not indexed by Lucene, so to be able to locate an empty field you need to index it with a dummy value – this dummy value can be specified here. |
|
HandleInheritedCategoryValues |
Boolean - defaults to False |
If True, inherited product category values are indexed. This is very slow, so please don't set this to true unless you really need to. |
|
HoursToUpdate |
An integer – not set by default |
If combined with the builder action Update, only the products updated within the hours specified here are rebuilt |
|
MaxProductsToIndex |
Integer – default is 2147483647 |
The maximum number of products to index |
|
OnlyIndexActiveProducts |
Boolean – defaults is False |
If set to True, only active products are indexed |
|
ShopsToIndex |
Comma-separated list of shop IDs |
This setting makes it possible to create indexes which only contain products from the specified shops/warehouses. |
|
SkipAllExtendedFields |
Boolean – defaults to False |
If set to True, the fields "CampaignStartTime", "CampaignEndTime", "CampaignShowProductsAfterExpiration", "IsVariant", "ManufacturerName", "AssortmentIDs", and "StockLocationProductAvailable" are skipped |
|
SkipCategoryFields |
Boolean – defaults to False |
If set to True, all product category fields are skipped |
|
SkipDetailImages |
Boolean – defaults to false |
If set to true, Details images are not indexed |
|
SkipExtenders |
Boolean – defaults to False |
If set to True, no custom Extenders can extend (update, remove, add) the fields in the index |
|
SkipGrouping |
Boolean – defaults to False |
If set to True, the fields "GroupIDs", "ShopIDs", "GroupNames", |
|
SkipGroupSorting |
Boolean – defaults to false |
If set to true, group sorting fields are not indexed – this may improve performance. |
|
SkipImages |
Boolean - defaults to False |
If true, image paths are not indexed |
|
SkipImagePatternImages |
Boolean – defaults to false |
If true, image pattern images are not indexed |
|
SkipPrices |
Boolean – defaults to false |
If true, product prices are not indexed |
|
SkipRelatedProducts |
Boolean – defaults to false |
If true, related products are not indexed |
ContentIndexBuilder
The ContentIndexBuilder is used for indexing content – pages, their paragraphs, and their item fields.
The index is built by enumerating all available pages, then handling active paragraphs & item fields for each page.
The corresponding schema extender – the ContentIndexSchemaExtender – contains the following types of fields:
- All fields from the Page table – e.g. PageActive, PageID, PageItemType, etc.
- A number of Page content fields:
- Paragraph headers contains an array of all paragraph headers on a page
- Paragraph texts contains an array of all paragraph text content on a page
- Paragraph content contains an array of the item type properties for each item-based paragraph on a page
- Page property item type contains the name of the item type used to extend the page properties of this page (if relevant)
- All item type fields in the format [item.SystemName]_[itemField.SystemName] and Property_[item.SystemName]_[itemField.SystemName], except the fields marked as 'do not include in search' in the item field settings.
- Possibly a number of App fields – see more below.
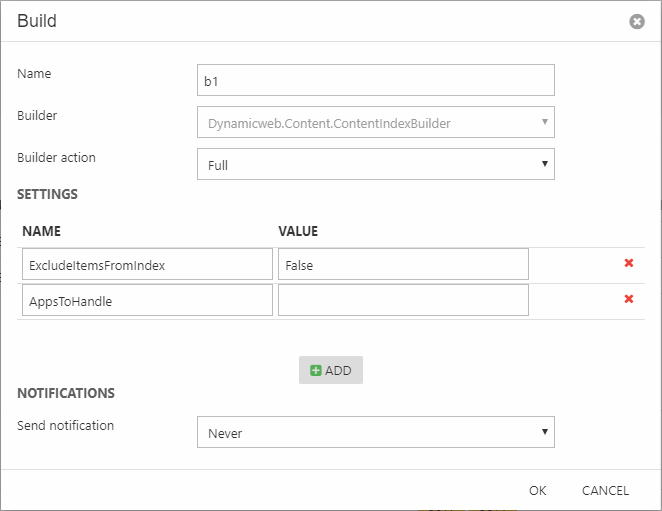
The following settings are available:
- ExcludeItemsFromIndex allows you to control whether or not item-based content should be indexed. False by default – which means item content IS indexed.
- AppsToHandle allows you to specify exactly which ContentAppIndexProviders to include. Valid input is a comma-separated list of ContentAppIndexProviders to include. If nothing is set here, all ContentAppIndexProviders are included.
By default, we deliver a ContentAppIndexProvider for the forum – review the API doc on the ContentForumIndexProvider here.
Due to complexity issues the ItemListEditor field type is not indexed.
Creating a custom ContentAppIndexProvider
If you want to extend the content index with app-specific fields or documents, you must create a class inheriting from the ContentAppIndexProvider Class and override the relevant methods.
As example please take a look at ContentForumIndexProvider class.
SqlIndexBuilder
The SqlIndexBuilder is used to index a table from the sql server database – it executes a query without manipulating any data. Currently only understands the builder action Execute.
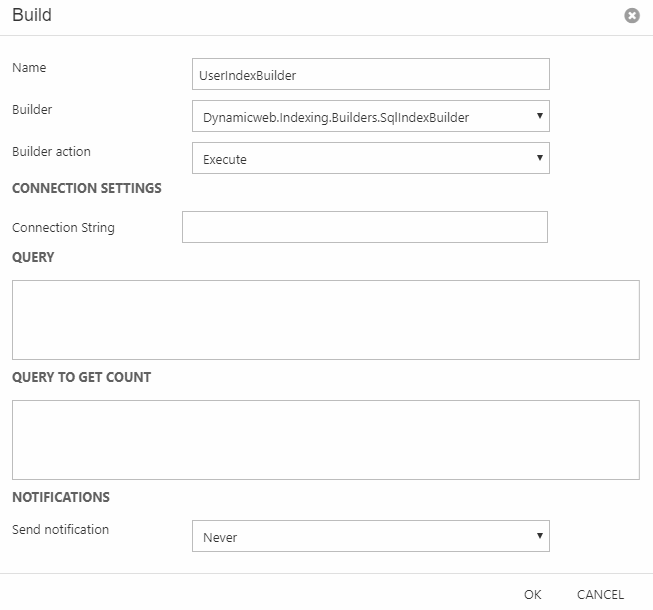
The following settings are available:
- Connection String can contain an SQL connection string, e.g. “Server=.;Database=test;User Id=sa;Password=sa;”
- Query can contain an SQL query which retrieves the columns and rows which should be indexed, e.g. “SELECT * FROM AccessUser”
- Query to get count can contain an SQL query which returns a count of the rows being added to the index, e.g. “SELECT COUNT(*) FROM AccessUser”
- UseStoredProcedure – a setting which can be set in the index XML config file. When set to True, the stored procedure name must be set in the “Query” setting which will be executed when running the builder to index the data.
UserIndexBuilder
The UserIndexBuilder indexes all fields on users, including custom fields (but not user behavior, like orders placed, or order value, etc.).
It executes the following query to retrieve users:
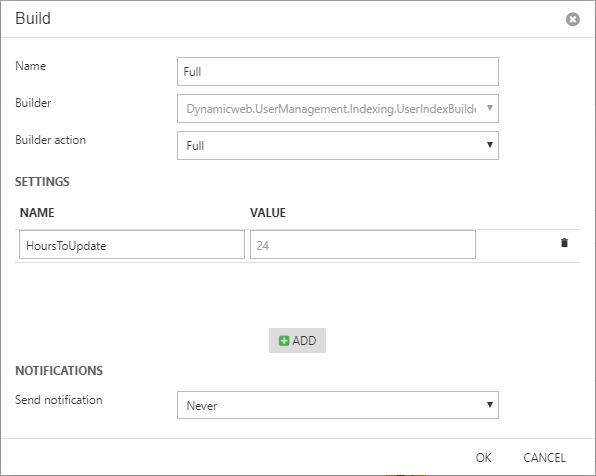
As of Dynamicweb 9.7, the UserIndexBuilder supports the following builder actions (Figure 8.2):
- Full builds everything from scratch
- Update rebuilds only the products which have been edited within the timespan which falls between the current time and the HoursToUpdate setting
- UpdateWithIds updates a set of users passed to the builder - this action is used by the system when a users is saved or user impersonation settings are changed
In addition to the standard user fields, the index contains the following generated fields for each user:
|
Field |
Field content |
|
Groups |
An array of user group IDs where the user is a member |
|
GroupNames |
An array of user group names where the user is a member |
|
Is Admin |
True if System Administrator or Administrator |
|
Combined order totals |
The sum of Order Price with VAT from orders completed by this user |
|
Largest order price |
Largest Order Price with VAT entry associated with this user |
|
Order count for last 30 days |
A count of completed orders associated with this user within the last 30 days |
|
Bought products |
An array of product IDs from order completed by this user |
|
Loyalty points total |
The sum of LoyaltyUserTransactionPoints from EcomLoyaltyUserTransaction associated with this user |
|
Loyalty point last added |
A DateTime entry of the last time loyalty points were added to the users |
|
Loyalty point next expirery |
Oldest loyalty point transaction date by the user summed with global setting /Globalsettings/Ecom/LoyaltyPoints/ExpirationPeriodInMonths |
FileIndexBuilder
The FileIndexBuilder (Figure 9.1) indexes various data about the files in the file system – NOT the content of the files. This can be used to create e.g. a searchable media library for images, pdf files, etc.
The following standard data is indexed:
- File name
- Directory path (/Files/whatever/Folder/OtherFolder/)
- Directory (OtherFolder)
- ParentDirectory (Folder)
- RootDirectory (Files)
- Extension (i.e. jpg, png, txt etc)
- Filesize in bytes
- LastWriteTime
The following fields are generated:
- FileFullName - file path and name
- Date created time/Date created time UTC
- Last access time/Last access time UTC
- Last write time UTC
- Is read only
We also index metadata (EXIF, XMP, and IPTC) for certain types of (image) files.
Currently, we can index metadata for following file formats; .pdf, .gif, .jpg, .jpeg, .psd, .bmp, .png, .tiff, .tif, and .ai.
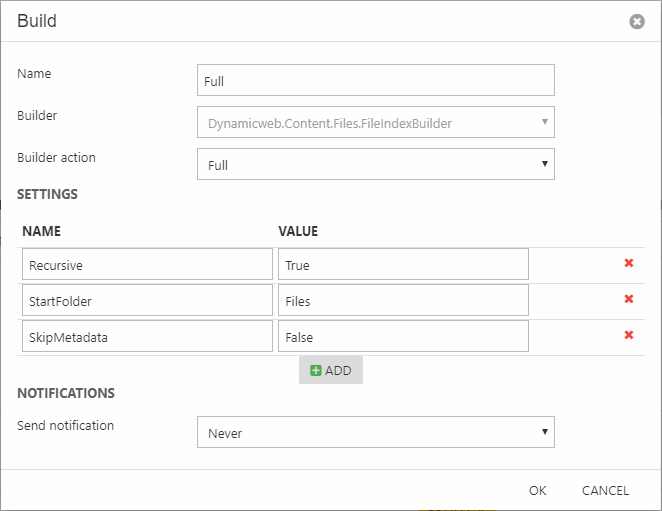
The following settings can be used to tweak the builder behavior:
- Recursive can contain a Boolean value, and controls whether subfolder content is indexed. Defaults to True.
- StartFolder contains the path to a folder, defaults to /Files.
- SkipMetadata contains a Boolean value, and controls whether metadata (EXIF, XMP, and IPTC) on image files is indexed.
Schema Extender fields
Fields are mappings between the data retrieved by the builder and the index – a set of instructions detailing which fields should be added to the index and how they should be stored.
To make things easier for you, we’ve created schema extenders for products, content and users – these are predefined sets of field mappings with everything defined for you.
To use a schema extender:
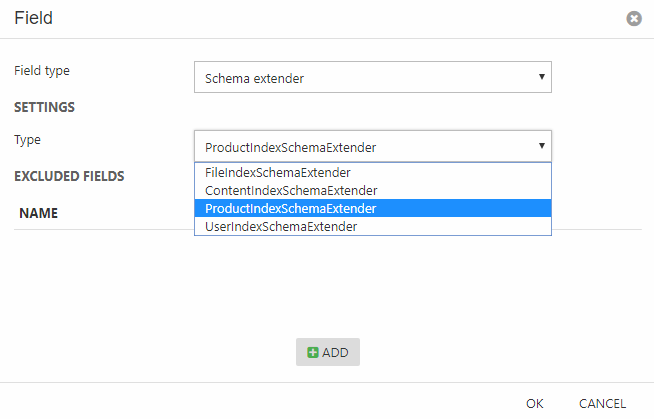
- Click Add field on the index configuration page to open the build configuration overlay (Figure 10.1)
- Select the schema extender field type
- Select the appropriate schema extender; FileIndexSchemaExtender, ContentIndexSchemaExtender, ProductIndexSchemaExtender, or UserIndexSchemaExtender
- Click OK
- Save
Once you’ve saved the index, you will see a list of fields provided by the schema extender in question, e.g. the fields provided by the ProductIndexSchemaExtender in Figure 10.2.
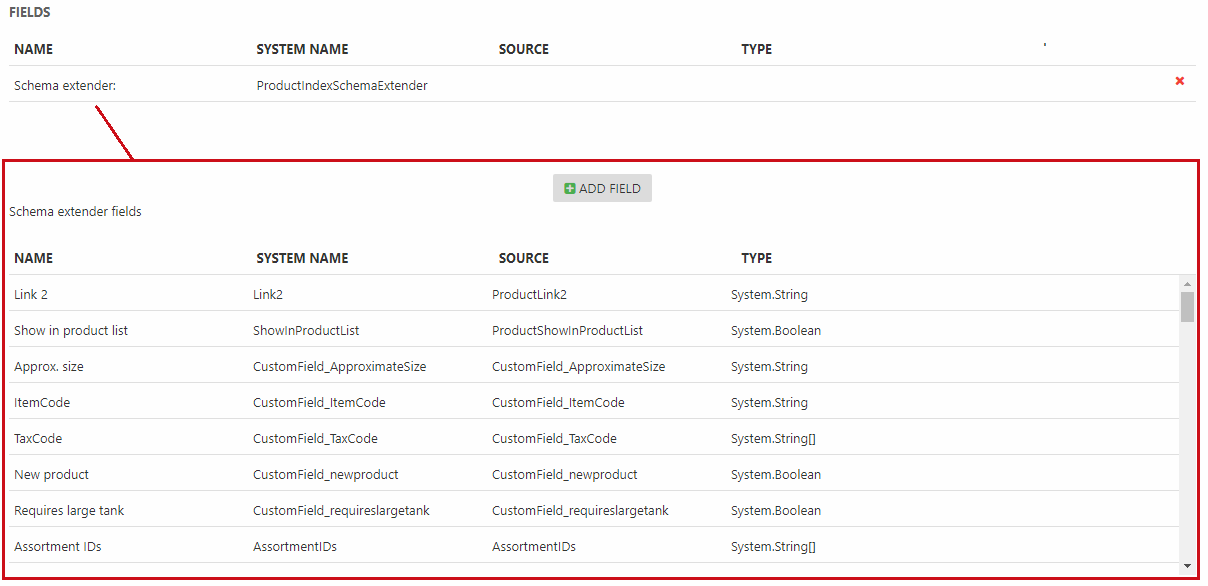
Now, the schema extender naturally makes some choices on your behalf – that’s the tradeoff with a predefined set.
Here are some headlines:
- All string type fields are analyzed by default which means that spaces are considered a divider (which in turn makes it possible to conduct free-text searches on the data).
- The fields cannot be assigned a custom boost value
If this behavior is a problem for your setup – which it often will be – you can exclude fields from the schema extender, and then add them manually and with the settings matching your needs.
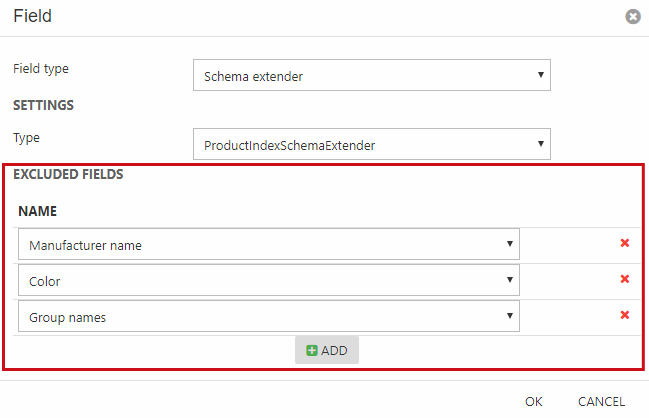
To exclude a field from the schema extender:
- Click the schema extender in the Fields area to open the settings (Figure 10.3)
- Under Excluded fields click Add
- Select the field(s) you want to exclude
- Click OK
- Save
The field will now be excluded the next time the index is built.