
File Indexes
A file index is used to index data about files on the system – NOT the content of the files. As such you can use file index to e.g. create searchable media libraries over images, pdf-datasheets, and so on.
It currently supports the following file formats:
- GIF
- JPG
- JPEG
- PSD
- BMP
- PNG
- TIFF
- TIF
- AI
To create a file index:
- Go to Settings > Repositories and open/create a repository
- Click Add index in the toolbar
- Name it
- Click OK
This creates an empty index (Figure 1.1) – you should now add instances to it.
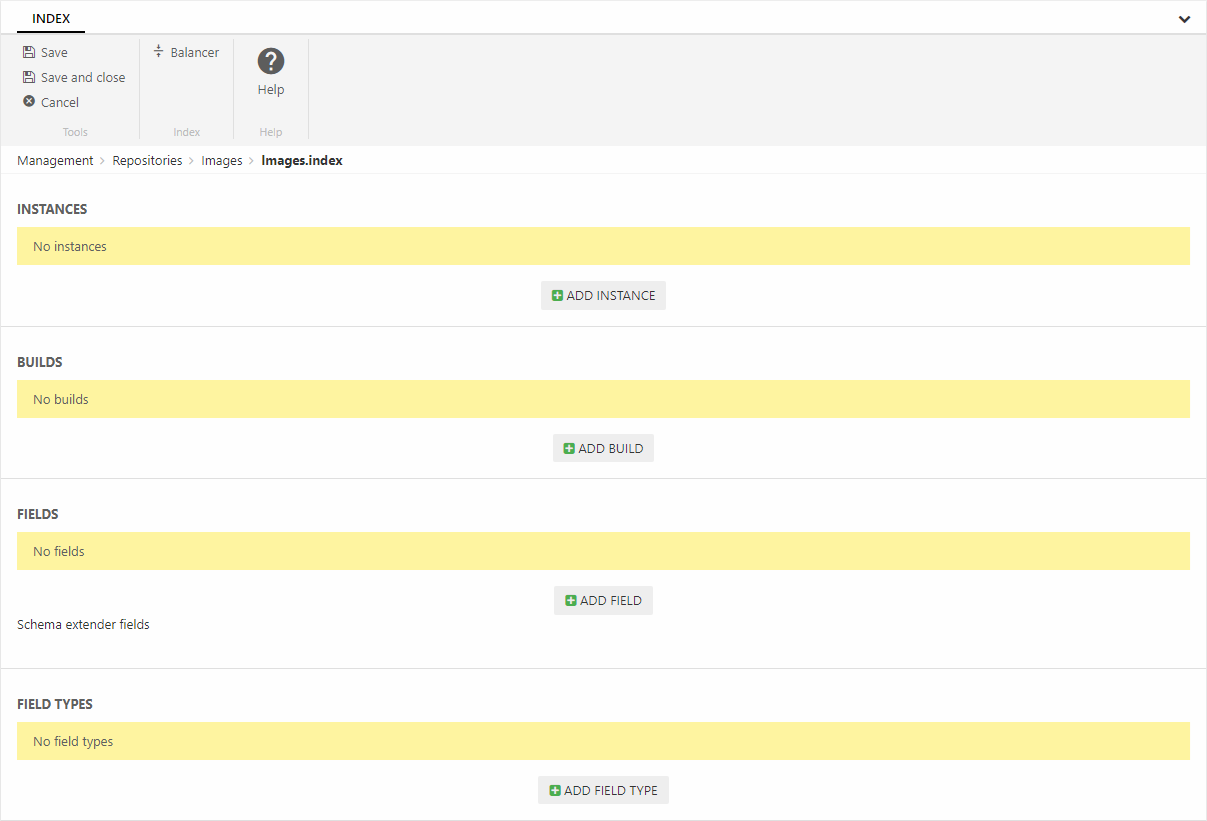
Adding instances
An instance is a file in the file archive – it is this file which is being searched when a query is executed. Since instances are often rebuilt to make sure they contain the most recent changes to product data you want to create at least 2 instances. This ensures that there’s always an instance to search, even if one instance is currently being rebuilt.
Create two instances:
- Click Add instance
- Provide a name – you could call one instance ‘Images A’ and the other instance ‘Images B’
- Specify a folder to place the instance file under
- Click OK
Once created your instances will look something like:
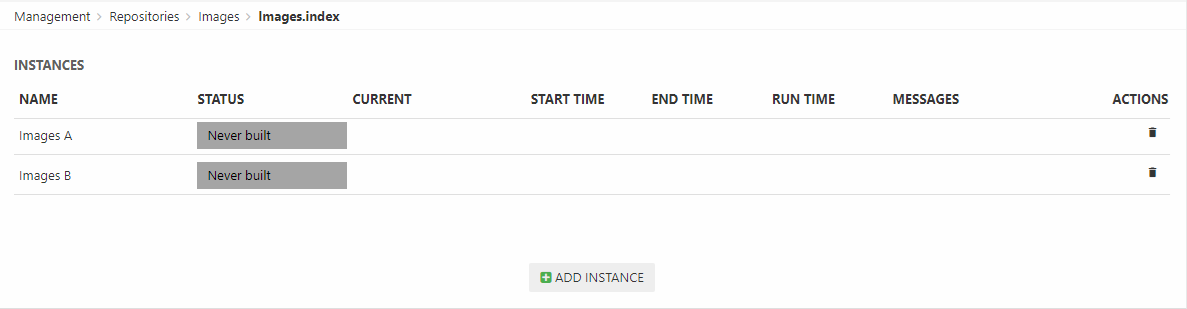
When an instance is built, a set of index files are generated under System/Indexes/YourIndexName/YourInstanceName – but before you can build it you must create a build configuration.
Adding a build configuration
So now that you have two instances you want to build them – to do so you need to create a build definition. Each type of index has a specific builder associated with it – in the case of a product index this builder is helpfully called the FileIndexBuilder.
To add the build configuration:
- Click Add build
- Provide a name
- Select the UserIndexBuilder
- Select a builder action – currently Full is the only action available
- Review the builder settings
- Set up notifications if appropriate
- Click OK
The following builder settings are available – please review carefully to see if any of them are relevant for your setup:
|
Setting |
Value |
Comments |
|
Recursive |
Boolean – default to true |
This setting controls whether subfolder content is indexed – by default it is. |
|
StartFolder |
Defaults to Files |
Controls which folder to index |
|
SkipMetadata |
Boolean – defaults to false |
Set to true to skip metadata like EXIF, XMP, IPTC on image files |
|
SkipDynamicwebMetadata |
Boolean – defaults to false |
Set to true to skip Dynamicweb metadata |
So now you’ve specified how you want the index to be built – you should now specify what you want to include in the index.
Adding fields
Lucene indexes are composed of small documents, with each document divided into named fields which contain either content which can be searched or data which can be retrieved. Each field added to the index can therefore be stored, indexed, and analyzed depending on what you want to use it for:
- Stored fields have their values stored in the index
- Indexed fields can be searched, the value is stored as a single value
- Analyzed fields have their values run through an analyzer and split into tokens (words)
Generally speaking, a field you want to display in frontend must be indexed and a field where you want the user to search for parts of the value in free-text search must be analyzed. Field which are to be published using the query publisher should be stored. Fields you want to display as facets should be indexed but not analyzed.
To make things (a lot) easier for you we’ve created a default set of fields typically used in product indexes – this default field set is defined in something called the FileIndexSchemaExtender.
To add the fields from the schema extender to the index:
- Click Add field
- Select the schema extender field type
- Select the FileIndexSchemaExtender
- Click OK
This adds a bunch of fields to the index (Figure 4.1).
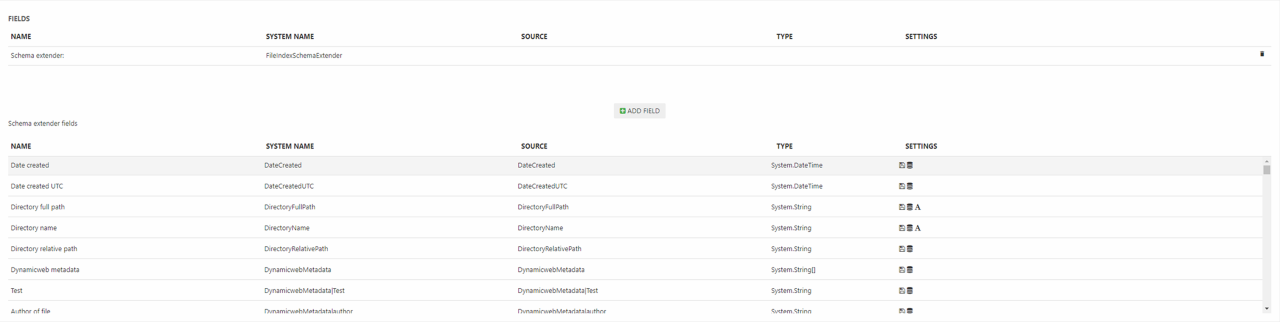
The following standard data is indexed:
- File name
- Directory path (/Files/whatever/Folder/OtherFolder/)
- Directory (OtherFolder)
- ParentDirectory (Folder)
- RootDirectory (Files)
- Extension (i.e. jpg, png, txt etc)
- Filesize in bytes
- LastWriteTime
The following fields are generated:
- FileFullName - file path and name
- Date created time/Date created time UTC
- Last access time/Last access time UTC
- Last write time UTC
- Is read only
We also index metadata (EXIF, XMP, and IPTC) for certain types of (image) files – currently .pdf, .gif, .jpg, .jpeg, .psd, .bmp, .png, .tiff, .tif, and .ai.
For each field you can see the Name, System Name, Source and Type – and whether the field is stored, indexed and analyzed. You can also add fields to the index manually – see the Custom Fields article.
Building the index
Once you’ve added instances, a build configuration, and a set of fields to the index you should build it – to do so click a yellow button with an instance name on it (Figure 5.1).
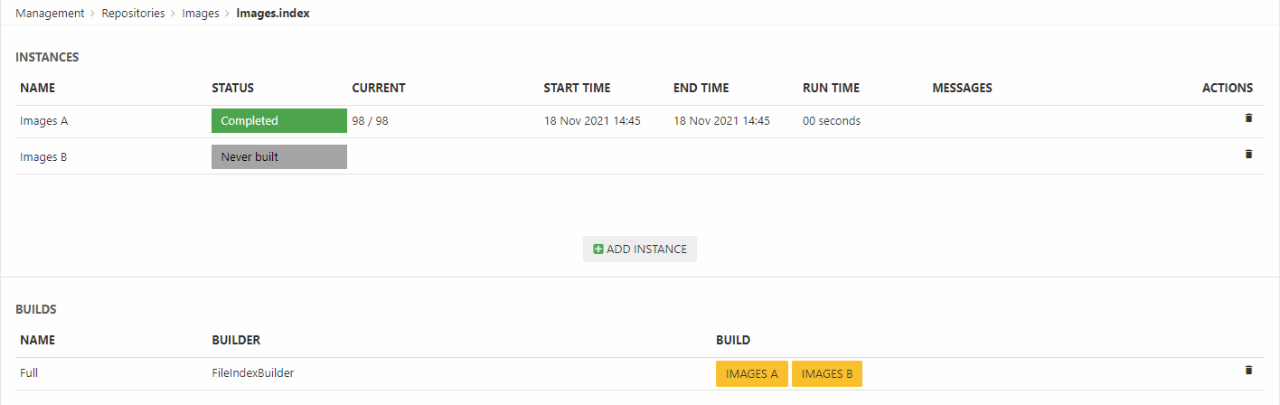
Of course, you don’t want to do this manually every time – you want to rebuild the index on a schedule – see the article on tasks.
If you have more than three instances defined you can also choose between two different balancing methods for selecting an alternative index when the primary index is being built:
- Click Balancer in the toolbar
- Choose between the two modes:
- ActivePassive selects the next instance on the list of instances – so if instance A is unavailable (building, has failed), instance B will be used unless it’s unavailable, in which case instance C will be used, and so on.
- LastUpdated selects the most recently built index
On solutions with heavy traffic and frequent product data updates we recommend using the LastUpdated mode to ensure that visitors are always shown the most recently updated product data. On solutions with only two instances (the vast majority of solutions) it is not necessary to select a balancer mode, as the “other index” will always be used when an index is unavailable.